


Mr. hamid reza
-
Content Count
45 -
Joined
-
Last visited
Posts posted by Mr. hamid reza
-
-
Hi
I need to define Matrix inside a feature. Definition of the multi-dimensional array makes my algorithm to be easy for implementation.
I found some objects such as "doubleseries" that can be applied for uni-dimension arrays.
I also see that there is solution for making a combination of "objectlist"s, but it does not seem a proper way in my case.
Is there any suggestion for defining a simple multi-dimensional array?
thanks in advance
Best Regards
Hamidreza
-
Hi Joerg
Thanks for your reply.
The "finaldata1.dat" is generated by Dakota, and it already contains the Pareto front. CAESES 4.4.1 changes some characters of the file, that is not readable according to conventions of Dakota. However, I do not see these changes when I use the CAESES 4.1.1, so maybe it is an issue that need to be fixed.
As the "finaldata1.dat" contains the Pareto members, I do not see any reason to regenerate them in the "run_best.csv", unless otherwise different method for recognition of Pareto front is used to generate the file. Is it so?
Best Regards
Hamidreza
-
Hello all,
I found some differences between the generated designs files of Dakota with CAESES 4.4.1 and CAESES 4.1.1. Considering that I am using the same version of Dakota 6.9 for both of them. I also use the same initial population for comparison the results in a multi objective problem.
Previously in CAESES 4.1.1, the generated files of Dakota had the “finaldata1.dat” as output of Pareto designs in the case of using MOGA.
Now in CASESES 4.4.1, the following outputs are observed:
- "run.csv" and "run_best.csv" are added in the output files of Dakota
- The “finaldata1.dat” shows some “nan” for the same evaluated equality constraints. However, in the CAESES 4.1.1, those value are shown as “0”, which means the constraints are passed according to the convention of Dakota.
- These are differences between the individuals in the files of “finaldata1.dat” and “run_best.csv”
So, the below questions come up:
1- Why does CAESES 4.4.1 changes the “finaldata1.dat”?
2- What kind of selection criteria are used for choosing the best designs in the “run_best.csv”? If it tries to copy the individuals in the “finaldata1.dat”, why there are some differences between the designs of the “run_best.csv” and the “finaldata1.dat”?
Thanks in advance
Best Regards
Hamidreza
-
Hello all,
I know there is a possibility of the connection between the CAESES and Poseidon as it is done in Harries et al. (2011).
is there any sample for such connection?
Thanks in advance
Best Regards
Hamidreza
-
Hi Joerg
Thanks for the reply. Actually, I do not know the reason of crash.
I am using the MOGA for the optimization, when I used the previous “results pool” for new start, CAESES generate new results and starts from beginning, some of the designs are referred to the marked "results pool" and some of them are not referred.
For example, imagen my goal is reaching to the 4000 Max. Evaluation. Then, the program is crashed after evaluating of 1000 individuals.
If I understood your suggested method well. When I use a results pool for repeating the optimization process, the CAESES start new optimization process from 1 to 4000 evaluations. If any of the provided individuals exists in the pool, it uses the evaluated results pool and do not calculate those ones. So it means, it do not starts from the point which is crashed.Is my understanding right?
If yes, there would be a difference with DAKOTA restart option. Because “the new executions of Dakota can pick up where previous executions left off.” So, it means, if I could use restart option of DAKOTA in my case, the DAKOTA engine could preview the history of optimization from the previous trial. In the new start, the GA would start form the 1001 individual and continue to the 4000.
Best Regards
Hamidreza
-
Hello all,
I am using the DAKOTA as optimization engine for solving my problem. Unfortunately, the process is crashed after preforming a lot of time consuming evaluations. But fortunately, DAKOTA can restart the process via the “DAOTA.rst” file.
In the DAKOTA manual mentioned that, the restart option starts the process from the beginning but uses the recorded previous evaluated functions(which is saved in the ".rst" file) and would continue from the point which is left without repeating the same function evaluations.
Is there any way to implement such useful option in the DAKOTA engine of CAESES?
Best Regards
Hamidreza
-
Hi
I am using the Dakota as the optimizer engine. Now, I need to introduce an initial population to the MOGA. It is possible via "flat_file" option for the "initialization_type", in the Dakota input.
As you my see in the Dakota email lists, the Dakota has removed the related bug to the mentioned option in the version 6.7, which is recently released. I replaced the content of Dakota tool ( "C:\Program Files (x86)\FRIENDSHIP-SYSTEMS\CAESES\tools\dakota\6.3.0" ) with the content of 6.7.0 version.
I also, created the “initial_population.dat” in the folder of Dakota input (“C:\Program Files (x86)\FRIENDSHIP-SYSTEMS\CAESES\etc\dakota”).
But still when I run the optimization with the related Dakota input, the process is beginning with the random initial population and do not use the “flat_file” inputs and I have the following error in the Dakota ".log" file, which means the the Dakota is not able to read the data:“quiet- flat_file: Encountered fatal error while attempting to read file "initial_population.dat". Make sure the file exists and is a JEGA Design flat file.”Is there any idea to help?
Best Regards
Hamidreza -
Hi Carsten
Honestly, I didn’t get your clue and some question appears for me:
- What do mean from “master project”, is it a kind of project that can be open with “many CAESES” at the same time?!
- What is the point of using the “connector”, while COM interface with external program do not require of such definition?
- How having “as many as CAESES instances” can help to improve the running time, while the problem is run time of external program? For example, I triggered two CAESES at the same time and ask them to run the COM connection with the external program, both of them just run one of the several triggered external program, it means , if I have a lot of triggered CAESES , all of them just can connect to one external program via COM connection!
And finally, I will appreciate you, if you have a sample to understand your suggested way.
Best Regards
Hamidreza
-
Hi Carsten,
I am using MAXSURF and I couldn't find batch mode access to the program.
Best Regards
Hamidreza
-
Hello Carsten,
Thanks for the reply.
Yes, the COM connection is fast, but the run time of external program does not related to the speed of connection, so the user may need parallel running of external program(s) for reducing the run time even if the CAESES is connected with the COM interface to other program(s).
At the moment , it seems that my run time can only improves by amendment of machine properties, which is running the external program. Do you have any other suggestion? if I want to connect to another machine for improving the run time, is there any possibility use COM interface with SSH?
Best regards
Hamidreza
-
Hello all,
I am running an optimization process using the Dakota MOGA and each design is evaluated using COM interface with external software. It means, any “connection setting” does not define, because the FFW communicate with the external software via COM interface. Unfortunately, it will be so time consuming, if I run it as usual. I need to reduce runtime.
By the way, I am able to use multiple instance of the external software on my machine, for example, I can open the external software five times and run an independent design on each one manually in the same time. So, the ideal process is using the parallel running the external software by FFW, then I can assess all designs in one generation in the same time. For example, at the same time that, the program is evaluating the first design, the second design would be evaluated by another license of external software on a single machine.
Considering the connection via COM interface and parallel running on one computer, is there any idea to help?
Best Regards
Hamidreza
-
Hi Stefan
Thanks, it works now
BR
Hamidreza
-
Hello all,
Is there any way to pass the output of the feature as input of some other features, without repetitive run of the referred one?
For example:
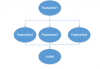
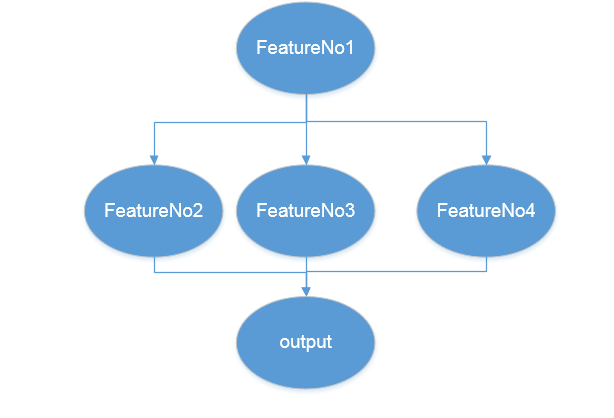
I am trying to run my algorithm as shown in the attached figure. At first the FeatureNo1 ran to get some inputs and calculate some values and objects. Then these value and objects have to pass to FeaturesNo2, FeaturesNo3, FeaturesNo4. For completing my process, I need to run all the Ffeaures.
I don’t want to combine all the features in one, because it will be so unclassified and difficult for tracing and development. So, I used the nested feature option and call the output of featureNO1 inside of each mentioned features (No2 to No4), then the features would be run in following order.
fp_ FeaturesNo2 no2()
no2.run()
Fp_FeaturesNo3 no3()
no3.run()
Fp_FeaturesNo4 no4()
no4.run()
Therefore, the FeatureNo1 run three times, because each feature calls the output of NO1 separately. So, is there any idea to escape of this repetition?
Best Regards
Hamidreza
-
Hi Stefan
I solved my problem by another way.
Actually instead of just copy and paste, I would like to suggest, the key control ability inside the Ffeature. :) I mean , sending the keystrokes to another program!
For example, in my case, I found that my external software do not support all the commands by COM interface. So the ideal process for me is sending the keystroke by CAESES Ffeature for doing some operation, which is not supported in the COM library of external software.
I don’t know, how difficult is implementing such application, but I found some free software that can do it.
Best Regards
Hamidreza
-
Hi Stefan
Thanks for your reply.
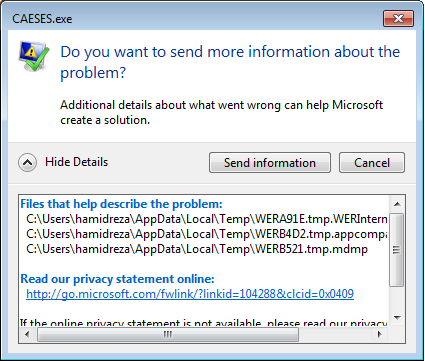
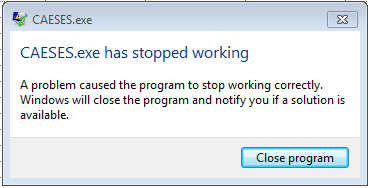
I like to explain my problem in other way. When I run the external program, the results of external program can only copied in format of table, on the Windows clipboard. So your suggestion means that the “FDesignResultsTable” can automatically paste the results from the Windows clipboard, it is right?
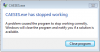
By the way, with running the “FDesignResultsTable” , the Windows stops the CAESES and the software will be terminated automatically, as you can see in the attached pictures.
I will be waiting for your reply.
best regards
Hamidreza
-
Hello all,
I am creating a Ffeature, which uses the COM interface to get some results from external software.
The results table of external software only can be copied to clipboard by available commands of its COM methods.
Now, I need to paste the data in a file or string variable and then extract my required values from those file or string. So, is there any command or method inside a Feature that can paste the data from the clipboard?
P.S.: I don’t have access to the “ResourceManager”.
Thanks in advance
Hamidreza
-
Hi Carlo
Thanks for the solution.
I think, the best way is defining the “persistent “ feature to have the capability of run in each design process, also, the outputs should define outside of the feature as you said. Thus, applying the” preprocessing commands” result in change the outputs according to input for each design.
Cheers,
Hamidreza
-
Hi all,
I provided a feature, it gets some designvariableparameters and the main output is a parameter too.
During the variation of each input the feature should be run to provide the relative output for using in optimization process.
If I use the “persistent features”, the output is not accessible in in the “evaluation “of “optimization engine”. On the other hand, if I use the “transient” feature, obviously the outputs don’t change with input variation.
Is there any idea to find the problem?
Cheers,
Hamidreza
-
Hi Joerg
Thanks for your reply, I have license of 3.1.4 ,so as I know, I can’t access to the Dokota interface, so I decided to work with available option in the CAESES, which is not supported by the detail unfortunately.
Do you have other suggestion? Especially, it is important to know, is there any technique to implement integer coding?
Cheers,
Hamidreza
-
Hello all,
I didn’t find a detail description about implemented methods of NSGA-II in the tutorial, for example I want to know:
- Which cross over method is used?
- What kind of mutation is applied?
- is there any possibility to define an integer design variable (including the integer coding inside the algorithm)?
- can I change the code of algorithm to satisfy my requests?
If you have any source, I will be thankful to know about that.
Cheers,
Hamidreza
-
Hi all,
Thank you Matthias, actually, I prefer the second method in my case, though it is not very user friendly. Also, I didn’t get the point of Mr. Iorga, but I like to suggest an option in future releases or maybe it exists and I don’t know, so please, inform me if there is.
Looking at the some 3D software, there is an option to get a 2D view of a defined arbitrary plan. These “ideal sections” includes all the requested entity of the made objects.for example, if plane is defined as longitudinal bulkhead for a ship, and the requested sectional view plan is defined like[1,0,0], a line can be seen in the section view. Also, these sections can be viewed in a separate layout (like FFW has in the 2D Window option) and has the ability of putting dimension lines and notes in that layout.Totally, it is useful for internal layout design.
Cheers,
Hamidreza
-
Hello,
I need to present my created ship hull and compartments, in 2D views in specified position.
I mean, the transverse sections or buttock or water lines presentation in specified length, breadth or height respectively.
Is there any idea to help?
Cheers
Hamidreza

-
Hi Stefan
thanks, the 3D view is working now.
but still, the file size is increased with adding the new objects, and even after removing them, it doesn't change.
Is there any option to decrease the size of the file, after removing the created objects? I mean some option like "Purge" in Autocad.
Cheers,
Hamidreza
-
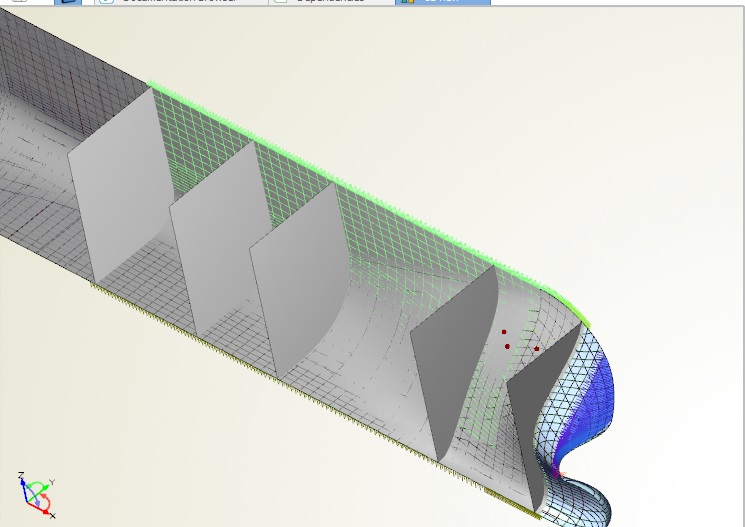
Hello,
I have produced some features on the sample of the FFW for container ship. It increases the size of the file form 906 k to 8072k, because I added a lot of object in my features.
Finally, I lost the 3D view presentation, I was suspected to the large size and many objects, but as you can see in the attached file, even after removing the objects and new built features, not only the size in not decreases but also the 3D view presentation is not work properly.
I wish , I could upload the main file to show you, but the CAESES site doesn't allow the attachment more than 5M!
Is there any idea to help?
Cheers
Hamidreza

multi-dimensional arrays
in Feature Programming
Posted · Report reply
Hi Jörg
Thanks for reply, It is nice to hear that such applicable functionality will be added in future.
I know How to use the doublesries and objectlist. but as you know, for making a tow-dimensional arrays by "objectelist"s, we need to replace each row with an objectlist, then the number of them increases. Moreover,we need to use castto() command frequently for each access to a simple double variable inside the list. I am worry about the increase the run-time ,especially when a lot of iterations and objectlist are needed during the process. does it?
Best regards
Hamidreza